

현대적 AI/IT 용어로 재구성: 통합 예측 분석 아키텍처
Tatacoa AI 솔루션의 핵심은 고급 분석 방법론을 실행하도록 설계된 **'통합 데이터 처리 아키텍처'**입니다. 이는 데이터 웨어하우스, 데이터 레이크와 같은 기존의 정적 데이터 저장소(historical data repositories)와 Kafka 이벤트 버스, IoT 플랫폼과 같은 실시간 스트리밍 데이터 소스(real-time streaming data sources) 모두와 원활하게 연동됩니다. 이러한 듀얼 모드(dual-mode), 즉 하이브리드(hybrid) 방식은 정교한 예측 기술의 포괄적인 적용을 가능하게 합니다.
핵심 시스템 기능
•종단적 및 시계열 분석 (Longitudinal & Time-Series Analysis): 시스템은 거래 데이터, 이벤트 로그, 과거 센서 기록과 같은 기존 데이터베이스 레코드를 수집 및 분석하여 복잡한 시계열 패턴을 모델링합니다. 이 프로세스는 운영 기준선(operational baselines)을 설정하고 신뢰할 수 있는 장기 추세 예측을 가능하게 합니다.
•실시간 멀티모달 이상 감지 (Real-Time Multimodal Anomaly Detection): 본 프레임워크는 온라인 러닝(online learning) 및 스트림 처리 모델을 배포하여 센서 데이터, 음성, 환경 오디오, 비디오, 이미지 등을 포함한 대용량의 멀티모달(multimodal) 데이터 피드를 실시간으로 분석합니다. 이 기능을 통해 설정된 기준선과의 중대한 편차를 즉시 식별하고 복잡한 이벤트가 발생하는 즉시 감지할 수 있습니다.
•맥락적 데이터 융합 및 강화 (Contextual Data Fusion & Enrichment): 본 솔루션은 대용량 스트리밍 입력을 기존 데이터베이스에서 추출한 심층적인 맥락 데이터와 상호 연관시킴으로써 실시간 분석을 고도화합니다. 이 프로세스는 단순한 데이터 포인트 분석을 넘어, 결정적인 **'맥락 인식(context-aware)'**을 제공하여 더 정확하고 미묘하며 설명 가능한(explainable) 예측을 가능하게 합니다.
•실행 가능하며 해석 가능한 인사이트 (Actionable & Interpretable Insights): 이 방법론은 이기종(heterogeneous) 엔터프라이즈 시스템의 이질적인 데이터 스트림을 '실행 가능하며 이해하기 쉬운(intelligible)' 예측으로 변환하도록 설계되었습니다. 이는 과거(배치) 데이터와 현재(스트리밍) 데이터를 통합하는 데 필요한 중대한 기술적 통합 및 데이터 오케스트레이션(data orchestration) 과제를 해결하며, 그 결과로 도출되는 인사이트가 강력할 뿐만 아니라 **'해석 가능(interpretable)'**하도록 보장합니다.


다음 Tatacoa AI 아키텍처들은 '하이브리드 데이터 컨텍스트(hybrid data context)' 내에서 예측 정확도, 도메인 적응성 및 운영 확장성을 기준으로 엄격하게 벤치마킹 되고 있습니다. 이 환경은 '정적 데이터(data-at-rest)'(기존 데이터베이스)와 '동적 데이터(data-in-motion)'(실시간 데이터 스트림) 모두를 통합 처리하도록 설계되었습니다.
A. 딥러닝(심층) 신경망 (DNNs):
- 분석 (정적 데이터/과거):
대규모의 기존 데이터셋(예: 거래 기록, 이벤트 로그, 시계열 센서 아카이브) 내에 숨겨진 복잡하고 비선형 적인 관계 및 **잠재적 특징(latent features)**을 자율적으로 발견하는 최첨단 **'표현 학습(representation learning)'**을 제공합니다.
- 요구 사항 (학습 단계): 상당한 **컴퓨팅 자원(GPU/TPU 클러스터)**을 필요로 하며, 방대하고 품질 높은 레이블링된(labeled) 기존 데이터셋이 필수적입니다. 따라서 효과적인 모델 학습과 예측 잠재력을 완전히 실현하기 위해서는 견고한 데이터 엔지니어링 및 MLOps 파이프라인이 반드시 요구됩니다.
- 적용 (스트리밍 데이터/현재): 학습이 완료된 모델 아티팩트는 **실시간 추론(inference)**을 위해 확장 가능한 인프라(예: 쿠버네티스 또는 서버리스 함수)를 갖춘 데이터 리치 환경에 배포하는 것이 가장 이상적입니다. 이를 통해 과거 데이터로 학습된 모델을 현재의 실시간 데이터 입력에 적용하여, 대규모의 고정밀 예측을 수행할 수 있습니다.
B. 대규모 언어 모델 (LLM)
- 분석 (하이브리드 데이터 컨텍스트): 실시간 비정형 데이터 스트림(예: 텍스트, 음성, 로그)을 기존의 정형 및 비정형 **지식 베이스(knowledge bases)**와 통합함으로써, 진보된 예측 및 생성 능력을 달성합니다. 이러한 융합은 심층적인 **'맥락 인식 추론(context-aware reasoning)'**을 가능하게 합니다.
- 강점: NLU/NLG (자연어 이해/자연어 생성) 작업에서 최첨단 성능을 보입니다. 이는 '생성형 분석' (예: 과거 이벤트를 기반으로 현재 시스템 상태를 동적으로 요약), 시맨틱 검색, 그리고 파운데이션 모델(foundation model) 아키텍처에서 파생된 도메인 특화 추론을 포함합니다.
- 적용 (하이브리드 아키텍처): 엄청난 확장성과 유연성을 제공합니다. 주로 '검색 증강 생성(RAG)' 기술을 통해 적용되며, 이 기술은 벡터 데이터베이스나 데이터 웨어하우스에서 가져온 실시간의 독점적인 정보를 모델의 컨텍스트에 동적으로 주입합니다. 이는 중간 수준의 MLOps 및 배포 복잡성으로 모델의 응답을 사실에 기반한 최신 데이터에 **'근거(grounding)'**시킵니다.
C. 딥러닝 (심층) 강화 학습 (DRL)
- 분석 (실시간 동적 데이터):'동적 최적화(dynamic optimization)' 및 자율 의사 결정 작업(예: 제어 시스템, 공급망 물류)에서 탁월한 정밀도를 달성합니다. DRL 에이전트는 환경 상태 및 보상 피드백의 실시간 데이터 스트림으로부터 지속적으로 학습하여 '정책(policy)'(의사 결정 전략)을 최적화합니다.
- 결합 (하이브리드 데이터 컨텍스트): 정책 또는 가치 함수가 딥러닝 (심층) 신경망(DNN)에 의해 근사화 되는 자율 에이전트를 구현합니다. 이 DNN은 종종 과거 데이터로 사전 학습된 강력한 '특징 추출기(feature extractor)' 역할을 합니다. 또한, 정적 데이터셋을 활용하여 **"오프라인 강화학습(Offline RL)"**을 수행함으로써, 실제 온라인 배포 전에 정책을 미리 학습시켜 샘플 효율성을 극적으로 향상시킬 수 있습니다.
- 적용 (순차적 의사 결정): 실시간 데이터 입력을 기반으로 한 현재의 행동이 미래의 상태 및 누적 보상에 직접적인 영향을 미치는 복잡한 '순차적 의사 결정(sequential decision-making)' 문제에 이상적입니다. 고차원의 '멀티모달 상태 표현(multimodal state representations)'(예: 비디오, 센서, 로그 데이터 융합)을 처리하여 고정밀 분석을 지원합니다.
이러한 진보된 **모듈형 아키텍처(modular architecture)**를 통해 Tatacoa AI는 정확하고 확장 가능한 예측 분석으로 측정 가능한 비즈니스 성과를 제공합니다. 이는 과거(정적 데이터) 및 실시간(동적 데이터) 인사이트 모두에 의존하는 복잡하고 빠르게 진화하는 운영 환경에 최적화되어 있습니다.


Tatacoa는 Bernardo Rincón Cerón과 Juan Manuel Carretero Toro 파트너가 설립한 기술 벤처입니다.
회사의 핵심 자산은 데이터 과학, 시스템 아키텍처, 응용 AI/ML에 대한 심층적인 전문 지식이며, 이는 검증된 시장 출시(GTM) 전략 및 애자일(Agile) 프로젝트 수행 역량과 통합되어 있습니다. Tatacoa는 효율적이고 영향력 있는 데이터 기반 솔루션을 엔지니어링하는 데 중점을 두고 있으며, 특정 클라이언트 프로젝트에 맞춰 비용 효율적인 맞춤형 기술 팀을 구성하는 데 탁월합니다.
회사 위치: 콜롬비아 보고타.
창립자
성공 사례
미국 조지아 공대
범위: 인신매매 피해자의 설문조사 데이터 분석.
활동:
설문조사 데이터의 데이터베이스를 구축했습니다.
하버드 대학 데이터베이스의 불평등과 Kaggle.com 의 소득에 대한 경제 데이터를 소싱하고 통합했습니다.
데이터 전처리를 수행했습니다.
마르코프 상태 전이 행렬과 그래프를 구축했습니다.
시간 중심 및 사회경제적 분석을 수행했습니다.
결과:
관련된 사람의 수를 포함한 인신매매 출처 및 목적지의 글로벌 지도(설문 조사 인구 기준).
시간 경과에 따른 중요한 변화를 감지하기 위해 지수 평활화를 사용하여 연간 총 사례 수를 분석합니다.
피해자가 관여하는 활동(예: "농업", "가사 노동", "매춘")을 "노동력", "성 관련", "노예 제도/착취"와 같은 범주별로 분류한 표입니다.
관련 국가 간 관계의 정도

참여 국가들 간의 관계 정도

성공 사례
SOP S.A.S. (블루베리 작물)
범위: 월별 및 연간 블루베리 수확량을 예측하는 AI 모델 구축.
활동:
사내 관측소에서 5분마다 수집한 작물 정보와 기상 데이터를 활용한 데이터베이스를 구축했습니다.
데이터 정리, 통계 분석, 데이터 엔지니어링(이상치 처리, 정규화) 및 상관 관계 계산을 수행했습니다.
8개의 다른 모델을 제작하고 생산을 위해 2개(월간 1개, 연간 1개)를 선택했습니다.
각 변수의 중요도를 계산했습니다.
예측 성능을 향상시키기 위해 중심 극한 정리를 사용했습니다.
결과:
2024년 월간 모델은 연간 누적 정확도 96%를 달성했습니다. 중앙값은 96%로 가장 높은 결과를 달성했습니다.
2024년 연간 모델은 누적 데이터에 대해 연간 94%의 정확도를 달성했습니다.
모형 변수들의 값과 엔벨로프 곡선을 제시한 무작위 선택 예시
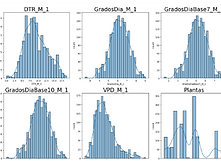
모델의 모든 수치형 변수들 간의 상관 지표

SOP S.A.S. (블루베리 작물)
목적: 작물 생산을 예측하기 위한 효율적인 AI 기반 솔루션을 제시하여 농업 고객이 데이터 기반 결정을 내리고 예측의 신뢰성을 높일 수 있도록 합니다.
해결된 작물 유형: 임시(수확 후 제거) 및 영구 작물(수확 후 남음)을 모두 포함합니다.
고려되는 변수: 관개, 계절학/작물 주기(파종, 개화, 수확), 기후, 토양 품질 및 생산 지표를 포함합니다.
분석적 접근:
v최소 2년의 과거 데이터를 사용합니다.
데이터 상태 인식, 잘못된 데이터 정리, 기술 분석, 변수 선택 및 상관 분석을 통해 모델 편향을 최소화합니다.
작물 생산성에서 각 변수의 중요성을 강조합니다.
v
예측 방법론:복잡한 다중 변수 농업 데이터를 처리하기 위해 랜덤 포레스트, 딥 러닝(심층 신경망), 지원 벡터 머신과 같은 AI 모델을 사용합니다.
사례 연구: 콜롬비아 지파키라의 블루베리 재배, 다양한 품종을 특징으로 하는 20개 로트; 목표는 여러 환경 및 운영 변수(기후, 로트 세부 정보, 시간)를 사용하여 다양한 기간에 걸쳐 생산량을 예측하는 것이었습니다.
결과 및 이점: 구현을 통해 자원 최적화가 향상되고 의사 결정이 향상되었으며 열대 농부의 예측 가능성이 향상되었습니다.
결론: 이해관계자들이 농업 생산성을 향상하고 운영을 최적화하기 위해 AI 기반 방법론을 채택하도록 초대합니다.

성공 사례
텍사스 대학교 오스틴 캠퍼스(묘목 분류)
범위: 이미지를 기반으로 묘목 종을 분류하는 모델을 구축합니다.
활동:
통계적 방법을 사용하여 데이터 분석을 수행했습니다.
12종의 다른 묘목 종을 분석했습니다.
서로 다른 신경망 기술을 사용하여 4개의 모델을 구축했습니다.
전이 학습을 활용한 가장 좋은 응답을 가진 모델을 선택했습니다.
분석된 12종 묘목 중 무작위로 선택된 묘목 이미지 예시

성공 사례
텍사스 대학교 해커톤 대회
결과: 2022년 2위, 2023년 4위.
컨텍스트: 이 프로젝트에는 "연간 매출액", "요리", "레스토랑 조마토 등급", "전체 레스토랑 등급"과 같은 변수가 포함된 레스토랑과 관련된 데이터 세트를 분석하는 작업이 포함되었습니다.
출력을 데이터 프레임에 저장한 다음 적절한 "등록 번호"가 있는 ".csv" 파일로 내보냅니다.

성공 사례
텍사스 대학교 오스틴 캠퍼스(은행 고객 유지)
범위: 6개월 동안 은행 고객의 유지율("퇴출" 여부)을 예측합니다.
활동:
"CreditScore", "Age", "Tenure", "Balance", "NumOfProducts" 및 "IsActiveMember"를 포함한 고객 데이터 변수를 분석했습니다.
데이터 정리 및 정규화를 수행했습니다.
단변량, 상관관계, 다변량 분석을 수행했습니다.
신경망을 활용한 4개의 AI 모델을 구축 및 분석했습니다.
결과: 최상의 모델이 선택되었습니다. 이 모델의 혼동 행렬(미세 조정 없음)은 0.843의 정확도를 달성했음을 보여줍니다.
Predict the retention of a bank customer within a 6-month period from a given point in time, based on the following list of variables

성공 사례
텍사스 대학교 오스틴 캠퍼스(은행 고객 유지)
범위: 6개월 동안 은행 고객의 유지율("퇴출" 여부)을 예측합니다.
활동:
"CreditScore", "Age", "Tenure", "Balance", "NumOfProducts" 및 "IsActiveMember"를 포함한 고객 데이터 변수를 분석했습니다.
데이터 정리 및 정규화를 수행했습니다.
단변량, 상관관계, 다변량 분석을 수행했습니다.
신경망을 활용한 4개의 AI 모델을 구축 및 분석했습니다.
결과: 최상의 모델이 선택되었습니다. 이 모델의 혼동 행렬(미세 조정 없음)은 0.843의 정확도를 달성했음을 보여줍니다.
The cities, regions, departments, and climate classifications considered are shown in the following table:

A.
한랭 기후 지역 (Cold Thermal Floor)
-
가장 강한 상관관계를 보였다.
-
0.99: 가입자 수 ↔ 총 소비량 (거의 1:1 관계)
-
0.82: 사회경제적 계층 ↔ 가입자당 소비량
-
한랭 기후에서는 사용자 수와 사회경제적 계층이 1인당 소비량에 매우 큰 영향을 미치기 때문에 소비 패턴의 예측 가능성이 높다.
B.
온대 기후 지역 (Temperate Thermal Floor)
-
중간 수준의 패턴이 나타난다.
-
0.96: 가입자 수 ↔ 총 소비량
-
0.73: 사회경제적 계층 ↔ 가입자당 소비량
-
-0.73: 지역 ↔ 총 소비량
-
이 경우 지역 요인의 영향력이 더 중요하게 나타난다.
-
또한 한랭 기후 지역에는 단 하나의 도시만 포함되어 있기 때문에, 이 경우에는 지역 개념이 중요하게 작용한다.
C.
건조 고온 기후 지역 (Warm Dry Climate)
-
비정형적인 패턴이 나타난다.
-
0.41: 사회경제적 계층 ↔ 가입자당 소비량
-
0.90: 가입자 수 ↔ 총 소비량
-
0.67: 지역 ↔ 가입자 수
-
이 경우 사회경제적 계층의 영향은 상대적으로 약하며, 지역 요인이 소비 변동성을 더 많이 설명한다.
-
특히 사회경제적 계층의 영향력이 다른 기후 유형보다 현저히 낮게 나타난다.
D.
습윤 고온 기후 지역 (Warm Humid Climate)
-
강한 상관관계가 나타난다.
-
-0.71: 사회경제적 계층 ↔ 가입자 수
-
0.73: 사회경제적 계층 ↔ 가입자당 소비량
-
-0.55: 지역 ↔ 총 소비량
-
낮은 사회경제적 계층 지역에서는 가입자 수가 더 많지만, 높은 계층의 사용자는 1인당 에너지 소비량이 훨씬 높다.
-
또한 지역 간 차이도 매우 크게 나타난다.
사회경제적 계층 비교 분석 (Comparative Analysis by Socioeconomic Strata)
